


Автор статьи: Полина Маенкова, главный технолог SEO-эксперт компании SEO.RU
- Что такое канонические страницы?
- Как указать канонический адрес?
- Для чего используются канонические ссылки?
- Откуда берутся дубли страниц в индексе ПС?
- Rel=canonical или 301 редирект?
- Частые ошибки
- Self-referential canonical
Что такое канонические страницы?
Начнем с определений.
Что такое каноническая страница? Это страница, которая для поисковых систем является главной среди всех остальных с похожим контентом.
Например, на сайте есть карточка товара — телевизора 66 с таким URL:
продавец-техники.ру/крупная-бытовая-техника/телевизоры/телевизор66
При определенных настройках настройках CMS открыть ее можно не только напрямую, но и, например, из раздела акций или Smart TV. Тогда у одного телевизора 66 будет несколько URL-адресов — и из них нужно выбрать оригинальную:
продавец-техники.ру/акции/телевизоры/телевизор66
продавец-техники.ру/smart-tv/телевизор66
продавец-техники.ру/доступно-в-рассрочку/телевизоры/телевизор66
Фильтры — не единственное, что генерирует такие клоны: мобильная версия, AMP и Турбо, пагинация и многое другое способно запускать технику клонирования.
Что такое каноническая ссылка? Это ссылка, содержащая атрибут link rel="canonical" и указывающая путь к канонической странице.
Каноническая ссылка размещается на неканонических страницах. Если предельно упростить, неканоническая отказывается от статуса канонической с помощью ссылки. Как бы передает его посредством размещения URL страницы-преемницы с атрибутом rel="canonical".

Если объяснения не помогли, а делать что-то нужно, закажите SEO-аудит у профессионалов: вы получите подробный перечень рекомендаций по улучшению всех сторон сайта.
Как указать канонический адрес?
Задать каноникал можно несколькими способами.
Использование готовых плагинов CMS
Некоторые CMS содержат внутренние решения для указания каноникал.
В Wordpress можно использовать YoastSEO — это бесплатный плагин, который поможет решить и другие задачи поисковой оптимизации.
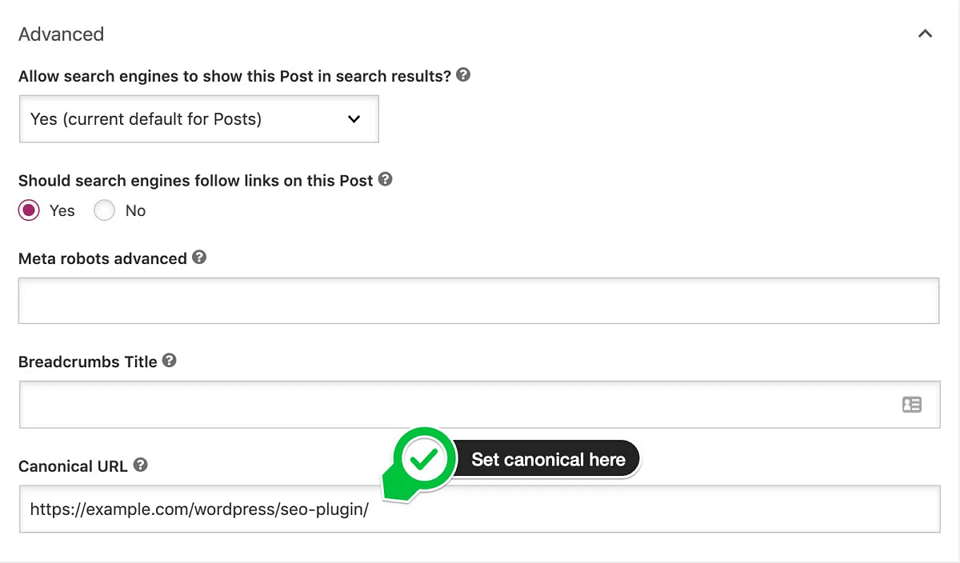
Для движка OpenCart разработано расширение SEO Canonical Links — правда, оно платное (20$):
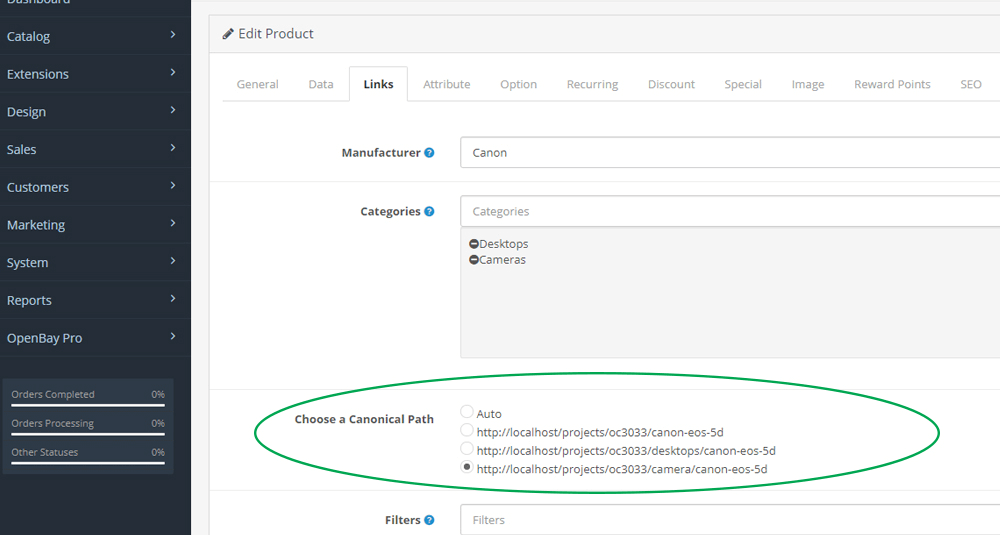
Для X-Cart — модуль SEO Ultimate (тоже платный — $59.00):
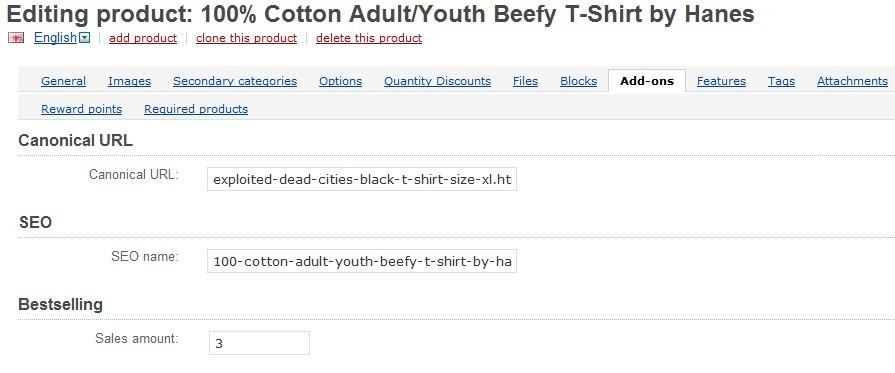
А для системы PrestaShop есть модуль Canonical SEO URLs + Google Hreflang Pro (за 69,99€ в год):
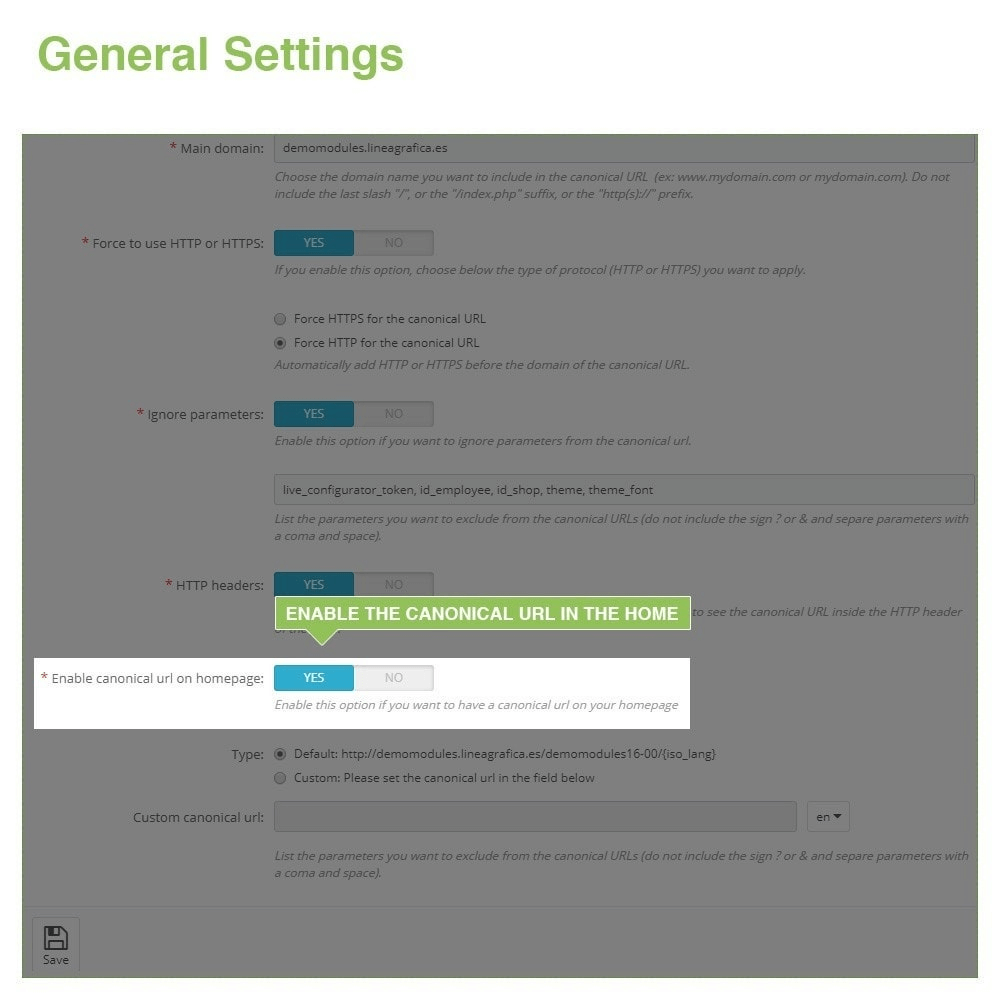
Если сайт реализован на система Joomla!, указать атрибут можно с помощью расширения Custom Canonical:
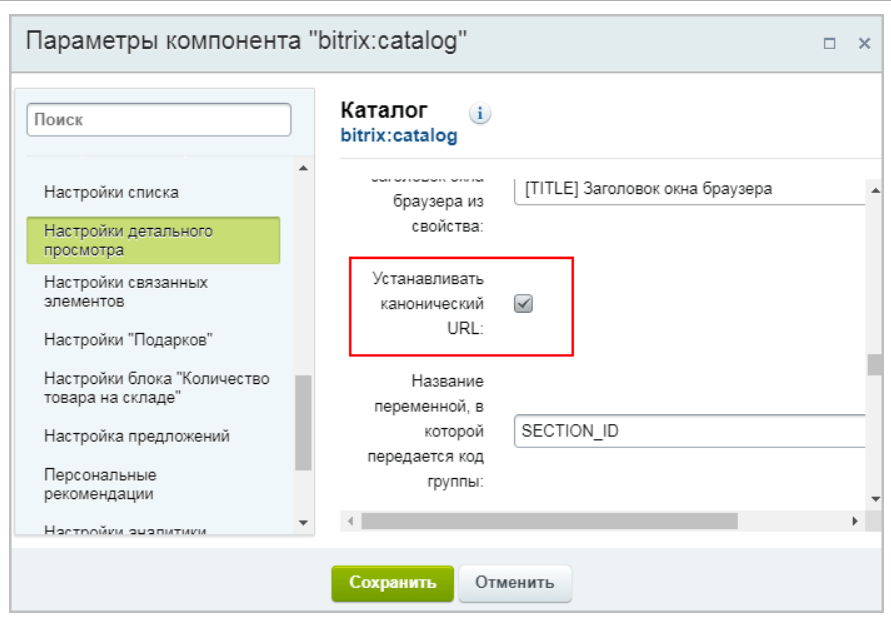
В Битриксе настройку canonical можно провести без установки дополнительных модулей— достаточно отметить соответствующую опцию в компоненте:
Внутренние функции CMS для работы с канониклами — это простой метод: не нужно перебирать строки кода каждой из неканоничных страниц.
Однако это не самый надежный способ: после использования средств движка или плагинов, стоит проверить наличие canonical и корректность работы.
Добавление элемента link в HTML-код
Этот способ — самый популярный. В HTML-код документа, внутри тега <head> нужно добавить элемент link rel="canonical".
В коде страницы это выглядит так:
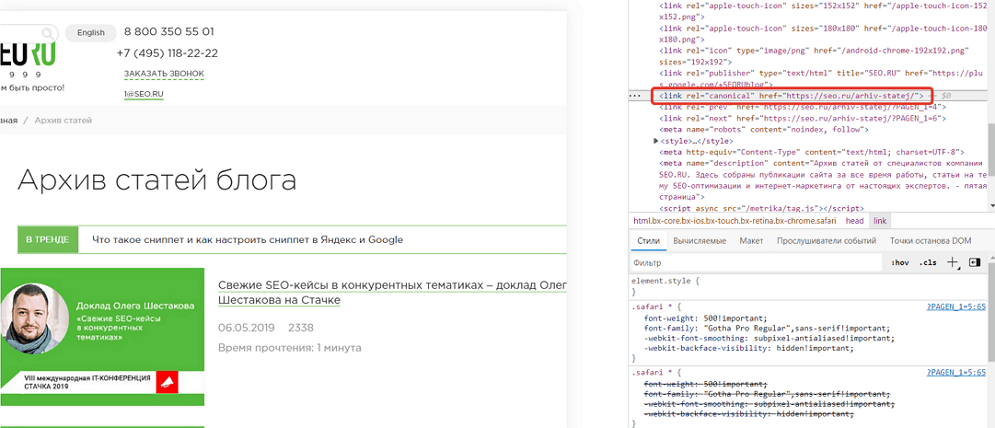
Каноническую ссылку нужно разместить в коде каждой дублирующихся страниц.
HTTP-заголовок
Как использовать canonical для канонизации ссылок на электронные документы (docx, pdf, xlsx и др.)?
Для подобных документов проблема дублирования тоже актуальна: один файл может быть доступен с нескольких URL-адресов. Эти форматы не подразумевают раздела <head>, как HTML-документы, поэтому и способ нужен другой.
Чтобы избежать атаки клонов и вытекающих последствий, нужно указать главный адрес посредством HTTP-заголовка с применением .htaccess или PHP.
Когда запрашивается дублирующийся файл, сервер должен перенаправлять на основной. На примере нашего примера с телевизорами — добавим ссылку на инструкцию:
HTTP/1.1 200 OK Content-Type: manual/pdf Link: <http://продавец-техники.ру/телевизор66/canonical-tags/>; rel="canonical"
Файл Sitemap
Файл Sitemap содержит ссылки, которые подлежат индексации, поэтому все указанные в карте сайта адреса имеют статус канонических. Не нужно указывать атрибуты или прописывать специальные теги. Главное — отследить, чтобы в файле sitemap.xml не было ссылок на дублирующиеся страницы. Иначе краулеры не смогут сориентироваться и правильно проиндексировать сайт.
Для чего используются канонические ссылки?
Главная задача использования каноникал — устранить риск попадания дублей страниц в индекс поисковых систем, чтобы они не засоряли выдачу.
Читайте по теме: Как найти и удалить дубли страниц на сайте? Инструкция
По этой причине поисковые системы борются с дублями: схожесть контента дает краулерам основания считать сайт непригодным для топа. Сайт начинает терять места в выдаче, снижается уникальность всего контента, из-за расплодившихся URL появляются проблемы с индексацией, создается внутренняя конкуренция между документами. Страницам даже необязательно быть совсем одинаковыми: когда бот видит несколько похожих вариантов наполнения, он может интерпретировать это как сигнал некачественного сайта. Но он может выбрать и добавить в индекс совсем не тот URL, который нужен в выдаче. Тут, правда, стоит отметить, что canonical для Яндекс и Гугл — это не прямая директива, а лишь рекомендация, и боты все равно могут включить в поиск другую страницу.
Однако указание canonical помогает избежать многих проблем при продвижении сайта.
Откуда берутся дубли страниц в индексе ПС?
Причин, по которым один и тот же контент доступен по разным URL-адресам, много. В некоторых случаях существование близнецов оправдано — то есть здесь нет никакой ошибки. В других же появление дублей сигнализирует о некорректной настройке сайта.
- Дубли по структуре.
В начале статьи мы приводили пример с URL карточки товара в магазине телевизоров и разными способами перейти к ней. Речь может идти не только о временных разделах типа акций, но и о постоянных разделах категорий.
- Страницы с GET-параметрами.
Источников появления параметрических страниц в индексе поисковых систем очень много (особенно это актуально для больших e-commerce сайтов):
- Страницы сортировки товаров (по убыванию/возрастанию цены, по популярности и т.д).
- Страницы результатов поиска по сайту (чаще всего содержит параметры s или q).
- Страницы фильтров по категориям.
- Ссылки с UTM-метками, которые используются для отслеживания переходов по рекламным источникам.
- Не настроен корректный ответ сервера для несуществующих URL.
Если на сайте не настроена страница 404, то любые вариации URL, которых нет в структуре сайта, будут отдавать ответ 200 ОК, т.е. будут доступны для поисковых роботов. Вероятнее всего, контент таких страниц будет дублировать содержимое каких-то существующих документов, например, страницу каталога.
Rel=canonical или 301 редирект?
Каноникал и 301 редирект передают поисковикам принципиально разные сигналы:
-
Rel canonical — это главная среди похожих: существует много URL с одинаковым или похожим контентом, но есть одна, которую нужно индексировать. Доступна и оригинальная страница, и ее сестры-близнецы.
Поэтому использование тега оправдано, когда все URL-адреса нужно сохранить доступными.
-
301 редирект — это новая взамен старой: существует одна страница, но не по старому, а по новому адресу, и именно новую версию нужно индексировать. Контент по оригинальному URL больше не доступен, его поисковая система исключает из индекса.
Настройка 301 редиректа нужна, когда старая страница окончательно удалена и взамен ее создана новая.
Сходства этих двух вариантов заключаются в том, что и 301 редирект, и каноникал передают сигналы ранжирования от одной страницы к другой. Под сигналами ранжирования здесь имеется в виду ссылочный вес страниц и поведенческие факторы (хотя последнее представители поисковых систем официально не подтверждают).
Частые ошибки
- Ошибка в написании канонического URL.
В HTML-коде важен каждый символ — из-за лишнего или недостающего заданный параметр не будет работать. Если canonical не работает, в первую очередь нужно проверить корректность его написания: все ли слеши указаны, корректный ли протокол (HTTP/HTTPS), полная ли ссылка.
- Два и более атрибута rel=canonical.
В этом случае поисковой бот может проигнорировать обе версии. Краулеры Google не смогут понять, какая из страниц является основной, и канонизируют URL по другим сигналам.
- Каноническая ссылка ведет на страницу с 301 или 404 ответом.
При таком сценарии канонической становится страница, которая уже должна быть удалена из индекса и с которой уже настроено перенаправление на новую. Из-за этого боты могут путаться и неверно истолковывать изначальный замысел. Лучше сразу канонизировать новую страницу.
Если каноническая ссылка ведет на URL с 404 ошибкой, сигнал канонизации просто никуда не передается и нигде не учитывается.
- Размещение rel="canonical" в секции body.
Это ошибка по невнимательности, сродни первому пункту. Атрибут rel = "canonical" работает только в tag <head> или в HTTP-заголовке.
- Каноничная страница закрыта от индексирования.
Если каноничная страница закрыта от индексации в файле robots.txt или с помощью директивы noindex в теге , краулер не будет сканировать ее, и страница не попадет в поисковую выдачу. Зато в таком случае в поиск может попасть ее дубль.
- Каноничная страница не имеет входящих ссылок.
Каноническая страница без внутренних входящих ссылок недоступна для пользователя. Значит, он перейдет на неканонический вариант и атрибут канонизации не сработает.
- Неканонические страницы в файле sitemap.xml.
Как описано ранее, все ссылки в Sitemap по умолчанию считаются подлежащими индексации. Неканоническим URL там не место.
Self-referential canonical
Атрибут rel="canonical" можно применять на самого себя: то есть канонизировать не какую-то другую страницу, а основную. Даже если на сайте нет ни дублированных, ни похожих страниц, данный URL-адрес будет индексироваться поисковыми ботами.
Кроме того, Джон Мюллер из Google рекомендует использовать самоссылающиеся каноникал из-за возможных разночтений версий в нижнем и верхнем регистре, а также при написании адресов с www и без них.








